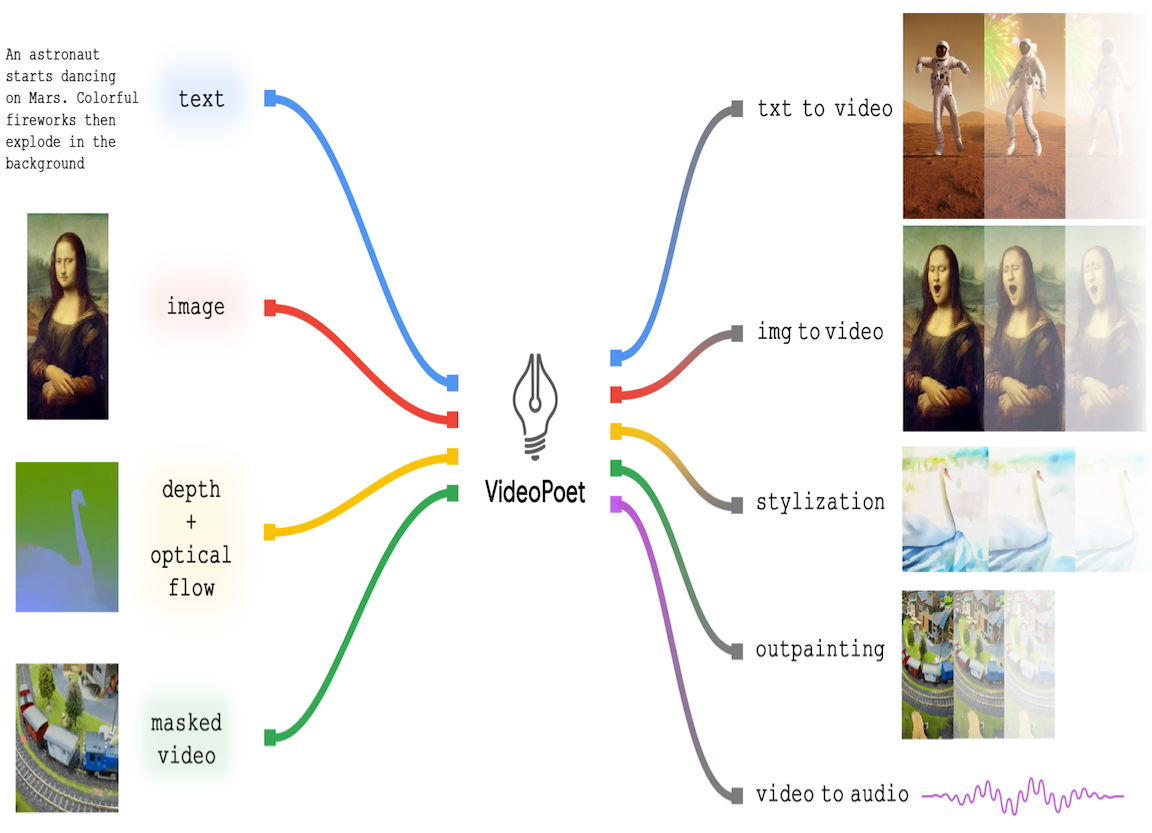
VideoPoet: A Large Language Model for Zero-Shot Video Generation July 23, 2024Best Paper Award; ICML 2024; Vienna, Austria
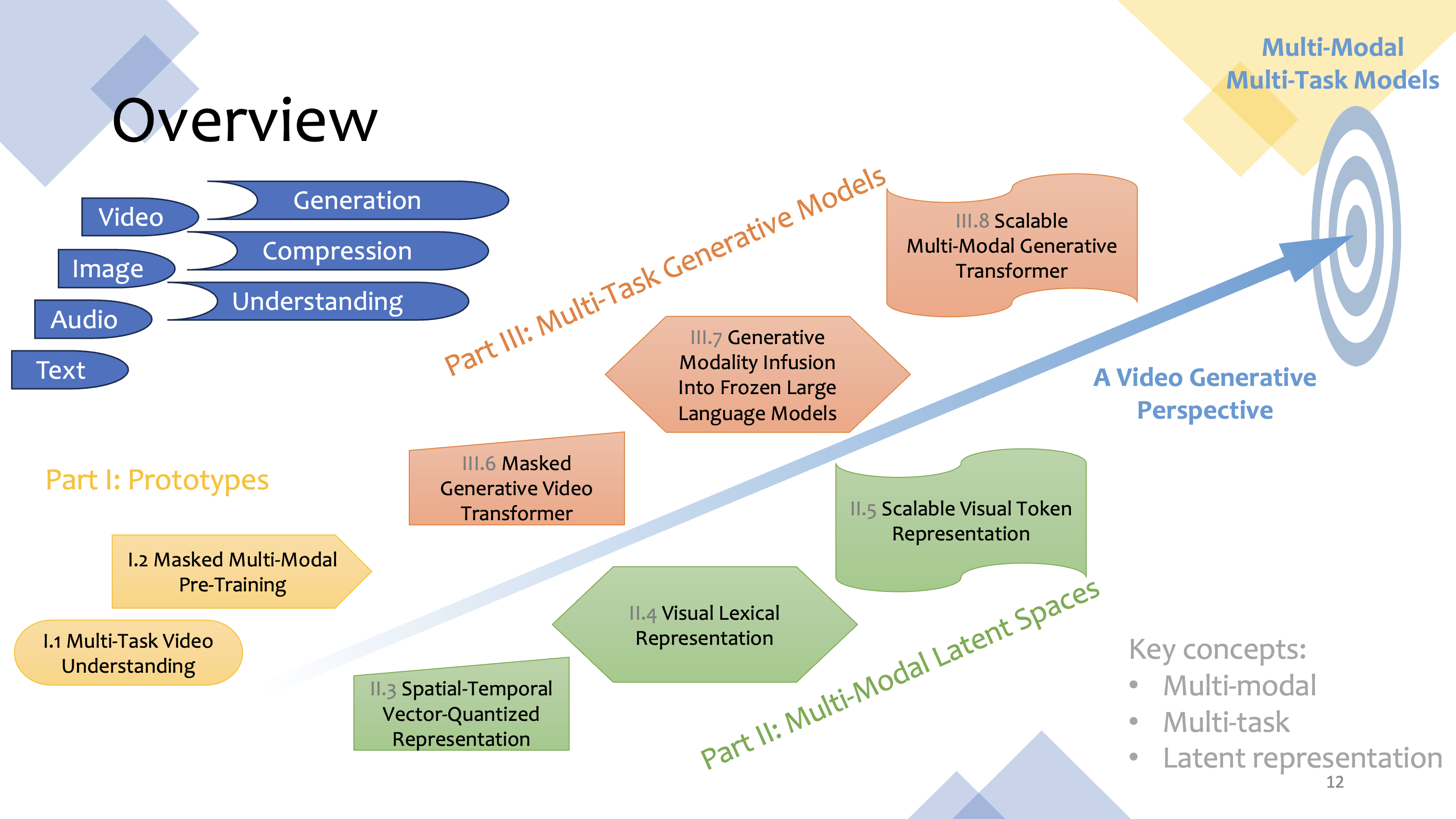
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective April 02, 2024Thesis Defense; CMU LTI; Pittsburgh, Pennsylvania
Language Model Beats Diffusion - Tokenizer is Key to Visual Generation January 09, 2024Invited Talks / Job Talks; HK-SH AI Forum, NYU, CalTech, HKUST, ICT CAS, Adobe, ByteDance, Baidu, Kunlun Tech, AIsphere, PKU AANC / OpenAI, xAI, Nvidia; Online and Beijing
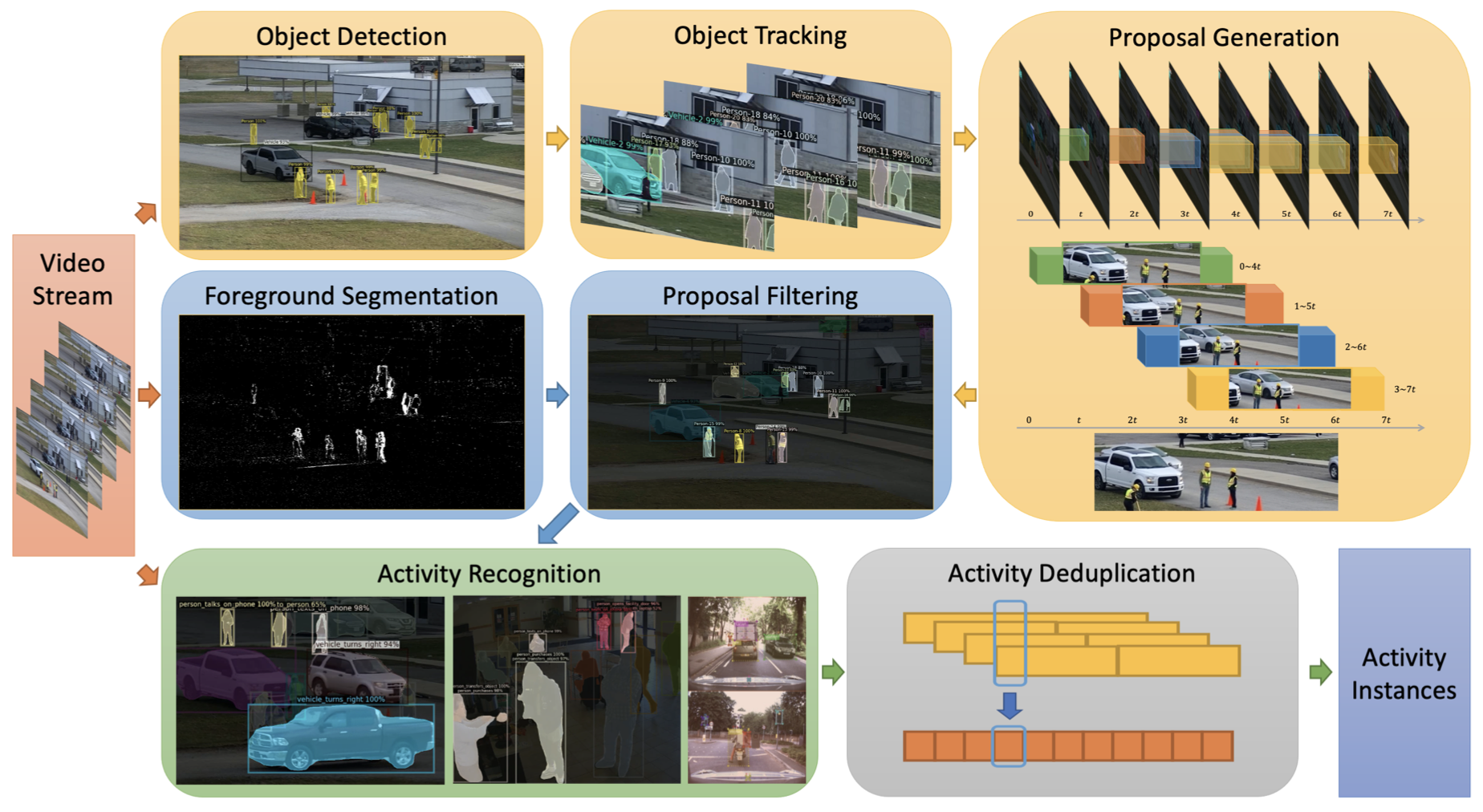
ArgusRoad: Road Activity Detection with Connectionist Spatiotemporal Proposals October 16, 2021Invited Talk; ICCV ROAD 2021; Virtual
Argus++: Real-time Activity Detection in Unknown Facilities with Dense Spatio-temporal Proposals June 18, 2021Invited Talks; CVPR ActivityNet / WACV HADCV 2021; Virtual
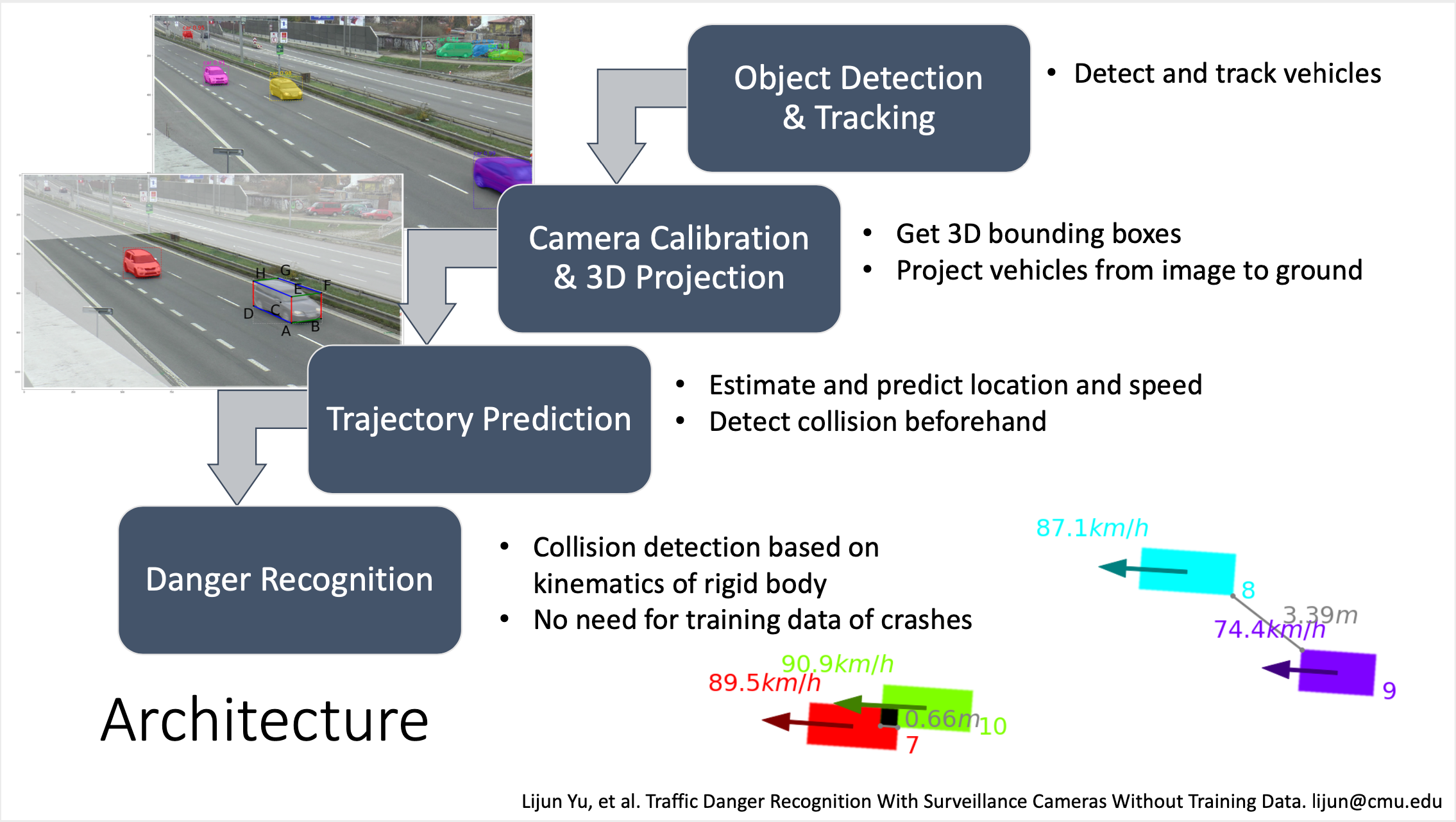
Traffic Danger Recognition With Surveillance Cameras Without Training Data November 27, 2018Invited Talk / Demo; TRECVID 2019 / ICCV 2019; Gaithersburg, Maryland / Seoul, South Korea